Criss-Cross Attention
Self-attention is one of the most powerful ideas in modern machine learning. It is also, famously, expensive, with O(n²) complexity in sequence length. For most language models, the sequence is made of word tokens. For cell foundation models, the sequence is made of genes. scPRINT-2 processes up to 3,200 genes per cell. That means 3,200² ≈ 10 million pairwise interactions, per layer, per cell. At scale, this becomes a real bottleneck.
This is not just a single-cell problem. The same pressure appears anywhere long contexts matter: reasoning models / agents, video models, genome-scale models, multimodal systems, and more. We wanted an attention mechanism that keeps the expressive power of attention while avoiding the brute-force cost of comparing everything to everything.
So we developed Criss-Cross Attention, a sub-quadratic attention mechanism that lets the model learn, in context, what should be compressed.
The Problem with O(n²) Attention
Standard self-attention computes pairwise interactions between every token and every other token. That exact all-to-all structure is what makes transformers so powerful, but it is also what makes them expensive.
In single-cell models, the issue shows up quickly. Gene contexts are long. scPRINT-2 was trained with up to 3,200 genes in context, and we already observed accuracy gains when extending to 8,000 genes at inference. Every increase in context length multiplies the compute and memory cost across all layers.
A large literature has tried to reduce this burden. Flash-Attention-31 makes standard attention much more memory-efficient through better kernel implementation, but keeps the same asymptotic complexity. Linformer reduces cost by projecting keys and values into a lower-dimensional space, effectively assuming that the attention map can be captured by a low-rank structure. Performer replaces exact softmax attention with a kernel approximation based on random features, yielding linear-time estimates of full attention. Flash-Hyper2 attention reduces work by routing computation toward query-key pairs predicted to be similar, using clustering and locality-sensitive hashing. Flash-Softpick3 keeps the dense structure but reshapes the softmax behavior to reduce attention sinks. These are all useful ideas, and we benchmarked several of them in our additive study. But they all start from the assumption that the modeler should choose in advance how attention gets simplified.
Criss-Cross Attention takes a different route. Instead of hard-coding a fixed approximation, it lets the model learn a compressed latent representation of the context, defined by the context itself, layer by layer.
The Idea: Compress First, Attend Through Latents
The core idea is simple. Not every token needs to attend directly to every other token. What matters is that each token can access a rich enough summary of the full context.
Criss-Cross Attention does this with a doubly cross-attention mechanism between the input tokens and a much smaller set of latent tokens. If the input is X and the latent set is L, the update becomes:
L' = Attention(Q=L, K=X, V=X)
X' = Attention(Q=X, K=L', V=L')
This keeps the same notation as standard attention, but changes the structure of the computation. Instead of computing attention from X to X, we first let the latent tokens read from the input, then let the input read back from the updated latents. The rest of the block remains transformer-like, with the usual normalization, residual pathways, and MLP updates, except that both the input stream and the latent stream are now refined across layers.
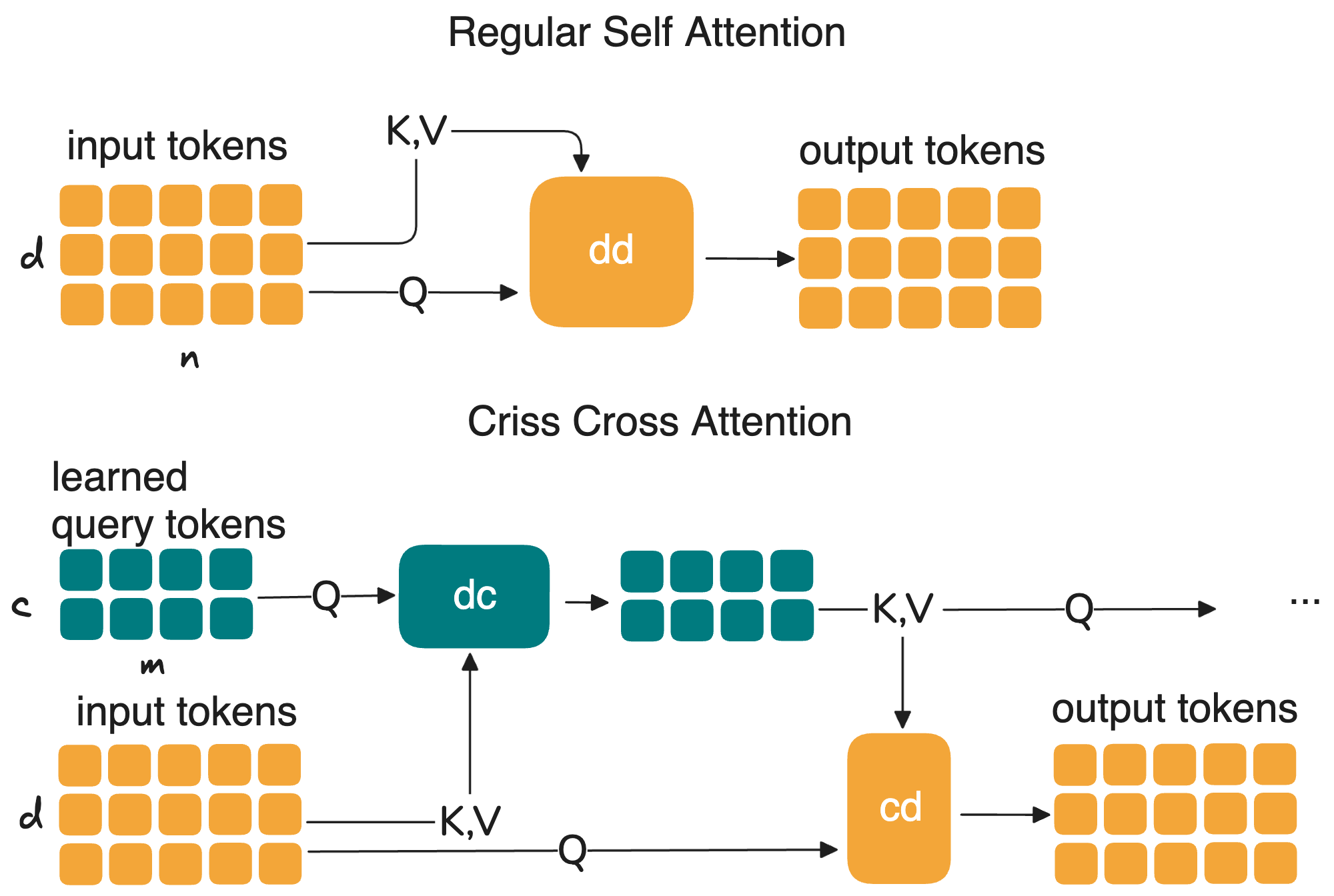
The cost drops from O(n²) to O(n × M), where M is the number of latent tokens and M ≪ n. If n = 3,200 and M is on the order of 100, the gain is already substantial. The point is not one exact compression ratio, but the fact that the cost now scales linearly with context length up to the latent bottleneck, rather than quadratically across all input tokens.
What makes this interesting is that the compression is learned in context. The latent tokens are not a hand-designed compression method. They are trainable representations that adapt to the input and are updated across layers. In that sense, Criss-Cross Attention behaves like a recurrent compression mechanism inside a transformer: each layer refines a compact working memory of the full context, and the input tokens repeatedly interact with that memory.
This is also why we see it differently from many efficient-attention variants. Rather than deciding ahead of time which entries of the attention matrix matter, we let the model decide what should be preserved in a compressed latent space.
A General Pattern Hiding in Plain Sight
Criss-Cross Attention is not an isolated trick. It belongs to a broader family of architectures built around latent bottlenecks, including the Induced Set Attention Block4, Perceiver-style5 models, and our own XPressor6 work. The common pattern is that a large input set communicates through a smaller learned latent representation.
What is new here is using that pattern as the main attention mechanism itself. In scPRINT-27, XPressor6 is a separate compression component. Criss-Cross Attention pushes the same logic into the transformer trunk, replacing full self-attention with alternating latent-to-input and input-to-latent updates. The latent space becomes a dynamic compressed representation of the cell state as it evolves through the network.
In our additive study7, this mechanism delivered substantial speed benefits with no reduction in benchmark performance. That result matters because it suggests that for many tasks, what we really need is not a dense n × n attention map, but a good learned compression of the context.
I think this is why the idea matters beyond single-cell biology. Models that do reasoning, multimodal fusion, long-context understanding, or concept formation all need to build compact internal representations from large amounts of input. In a way, concepts themselves are compressed summaries of rich multimodal features. Criss-Cross Attention makes that compression explicit and learnable inside the attention mechanism.
-
Shah, J., Bikshandi, G., Zhang, Y., Thakkar, V., Ramani, P., & Dao, T. (2024). FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. NeurIPS 2024. arXiv:2407.08608 ↩
-
Han, I., Jarayam, R., Karbasi, A., Mirrokni, V., Woodruff, D., & Zandieh, A. (2024). HyperAttention: Long-context Attention in Near-Linear Time. ICLR 2024. arXiv:2310.05869 ↩
-
Zuhri, Z. et al. (2025). Softpick: No Attention Sink, No Massive Activations with Rectified Softmax. arXiv:2504.20966 ↩
-
Lee, J., Lee, Y., Kim, J., Kosiorek, A. R., Choi, S., & Teh, Y. W. (2019). Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. ICML 2019. arXiv:1810.00825 ↩
-
Jaegle, A., Gimeno, F., Brock, A., Zisserman, A., Vinyals, O., & Carreira, J. (2021). Perceiver: General Perception with Iterative Attention. ICML 2021. arXiv:2103.03206 ↩
-
Kalfon, J. et al. (2025). Towards Foundation Models that Learn Across Biological Scales. bioRxiv. doi:10.1101/2025.05.16.653447 ↩ ↩2
-
Kalfon, J. et al. (2026). scPRINT-2. In revision, Nature Methods. ↩ ↩2




Leave a comment